阅读NVIDIA CUDA Programming Guide一些笔记
Why CUDA
一句话官方定义CUDA:
CUDA是一种利用NVIDIA GPUs中的并行计算引擎来高效解决复杂计算问题的通用高并行计算平台和编程模型
理解Why CUDA就是理解Why GPU。GPU与CPU的设计决定了其使命,GPU中大量的晶体管用于数据处理比如浮点数计算。在同样面对读写内存的延迟问题时,GPU通过高度并行计算来弥补这种不足,而CPU则依赖多级缓存和复杂的流控制来解决,后者从晶体管的角度看具有非常昂贵的开销。这就导致了在进行并行计算时GPU具有天然、显著的优势。因为CUDA目的是作为一个通用的并行计算平台和编程模型,所以其将执行并行计算的设备抽象为device,而将准备数据,调用并行计算设备的设备抽象为host,以下我就分别以GPU和CPU指代了。
编程模型
线程层级
理解CUDA,只需要理解这几个概念。Kernel,Thread,Block,Grid。
Kernel:CUDA C++允许我们定义的函数方法,使用__global__声明,调用时使用<<<...>>>语法定义执行使用的Thread、Block配置。一旦调用,会由GPU中声明的N个线程并行执行。Thread:执行Kernel方法的单位。Block:组织Thread的结构。Grid:组织Block的结构。
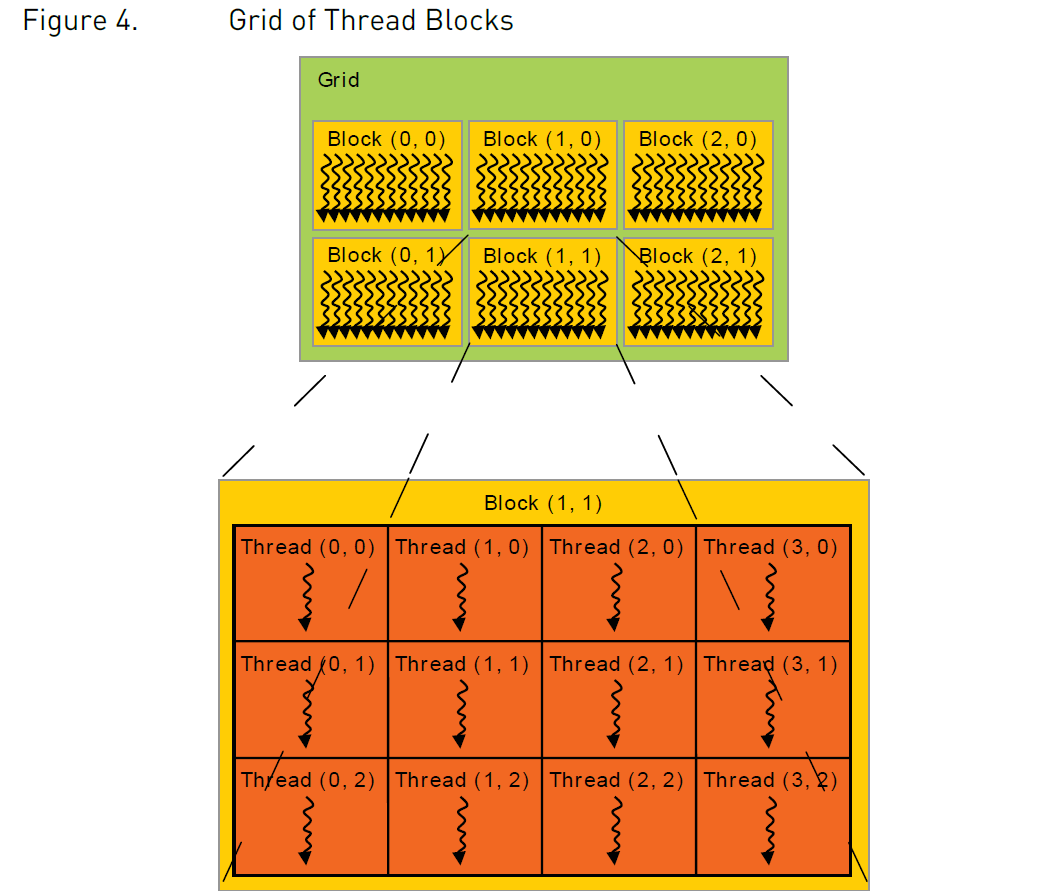
图1:线程、线程块、线程格的结构
在调用CUDA Kernel时,我们可以指定用多少个Block,即blocksPerGrid,亦即gridDim,再指定一个Block中有多少个Thread,即threadsPerBlock,亦即blockDim。比如对一个N * N矩阵的加法,可以如下调用Kernel。
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N]) {
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main() {
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd <<< numBlocks, threadsPerBlock >>> (A, B, C);
...
}
在该例中,我们指定一个Grid只有1个Block,一个Block中有N * N个Thread。对于blocksPerGrid与threadsPerBlock,我们可以给一维,二维甚至三维的维度(int或者dim3),来适应向量,矩阵与图像,甚至体素的并行计算问题。只是当我们给的维度不足时,剩余的维度默认为1而已。
threadsPerBlock有上限,首先其总数有上限1024,与硬件有关,且其维度也有不同的限制,比如第三维度最高只能到64。你可以给(1024,1,1)或者(1,1,64)。
在Kernel方法中,我们可以通过其索引index来对不同线程进行区分,用于进行不同的计算任务。这需要用到内建(built-in)的变量:
blockIdx:线程块的索引,是一个三维unsigned int型变量threadIdx:线程的索引,是一个三维unsigned int型变量gridDim:即blocksPerGrid,调用Kernel时传入的第一个dim3blockDim:即threadsPerBlock,调用Kernel时传入的第二个dim3
这里要注意,索引只是相对位置,或者说块/格子内位置,要计算一个线程的绝对位置(往往我们需要的是线程的绝对位置,来读写取对应的显存地址),则需要结合gridDim与blockDim来计算。这里引用一下Guide中的原文做补充说明。
The index of a thread and its thread ID relate to each other in a straightforward way: For a one-dimensional block, they are the same; for a two-dimensional block of size (Dx, Dy),the thread ID of a thread of index (x, y) is (x + y Dx); for a three-dimensional block of size (Dx, Dy, Dz), the thread ID of a thread of index (x, y, z) is (x + y Dx + z Dx Dy).
再通过一个矩阵相加的示例来说明:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
上述示例将线程的二维相对索引threadIdx结合线程块的索引blockIdx与线程块的结构blockDim展开成了绝对的二维索引i,j,对应最终矩阵中的行列坐标。你可以对照图1理解,若干个线程块二维排列起来,那么当前线程的横坐标等于块内相对横坐标(即threadIdx.x)加上之前线程块累积的横坐标(即blockIdx.x * blockDim.x),纵坐标也同理。
值得注意的是,该例子中为了方便假定N / threadsPerBlock.x可以整除,其实这种假定往往不成立。现实中往往要通过divideAndRoundUp来向上取整,也就是说较问题规模而言会至多分配一个线程块,所以需要在每个线程中做有效性判断if (i < N && j < N)。
// divideAndRoundUp,N为问题规模,即最终需要的线程数
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
综合而言,使用CUDA编程时,我们需要将问题划分为若干个相同的子问题求解,按照某种形状组织起子问题,然后在GPU中由线程去执行每一个子问题,并行计算得到结果。每一个线程所执行的方法是一样的,唯一的区别是其index索引不同,根据其不同的位置索引,去访问不同的显存数据作为输入,再输出结果到对应的显存地址中去。
显存层级
在执行Kernel期间,每个CUDA线程可以从多个存储空间访问数据。
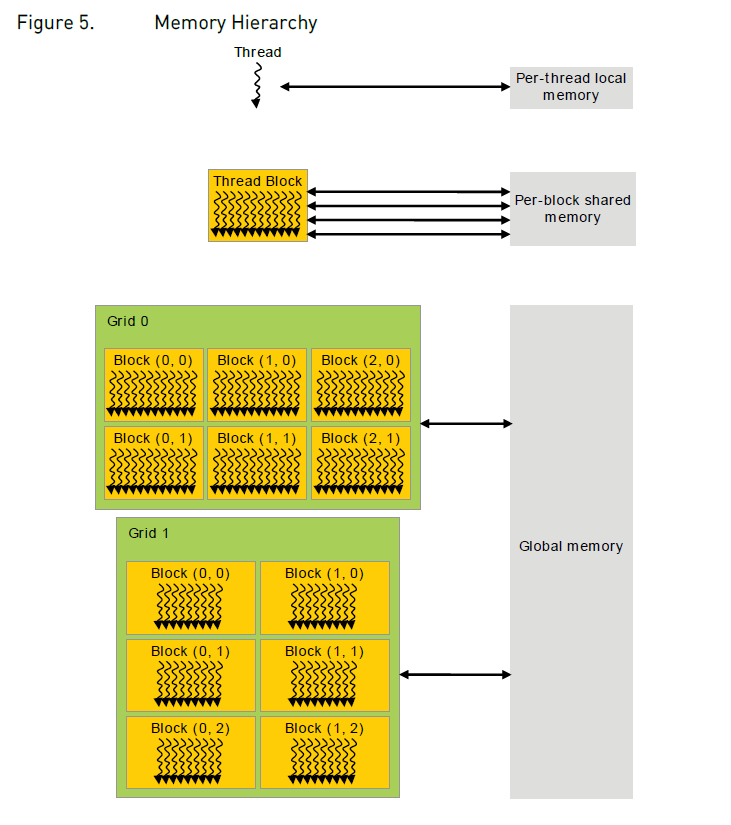
图2:内存模型
- local memory: 线程私有空间
- shared memory in block: 线程块块内共享空间
- global memory: 所有线程共享空间
- constant memory: 所有线程共享的只读空间
- texture memory: 所有线程共享的只读空间
global、constant、texture三种显存空间是所有线程均可访问的,不同在于其针对不同的使用方式和数据做了针对性优化,如一级缓存,空间访问局部性原理等。
混合编程
并非所有的代码都需要并行计算,也并非整个程序都执行在GPU上,一个使用CUDA编写的程序往往是这样执行的:
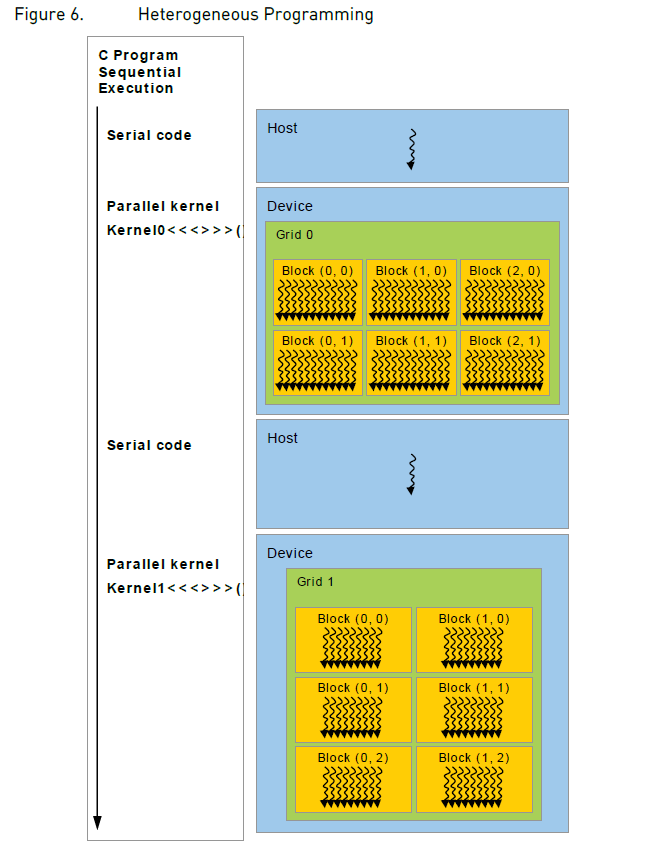
图3:CPU/GPU混合编程的执行顺序
Kernels,即并行计算执行在GPU上,剩下的顺序执行部分执行在CPU上。并且CUDA编程模型还会假设二者拥有自己独立的内存空间。所以我们编写的程序需要通过CUDA runtime提供的接口去管理以上所提到的所有内存,包括GPU内存的分配和释放,以及GPU和CPU之间内存的数据传输。
虽然目前看大部分计算机都是CPU和GPU内存相互独立,但是从未来角度看,统一内存(如苹果M1)统一了CPU GPU的内存地址空间,减少了二者之间的数据拷贝、传输、存储的开销,应该逐渐会成为主流。
异步单指令多线程编程模型 Asynchronous SIMT
从安培架构的NVIDIA GPU开始,CUDA就通过异步编程模型加速了CUDA线程对内存的操作。该编程模型通过异步屏障Asynchronous Barrier这类同步对象来实现CUDA线程之间的同步,也解释了为什么我们可以通过cuda::memcpy_async接口在GPU仍在计算的过程中从global memory中异步操作数据。
同步对象除了cuda::barrier外,还有cuda::pipeline,异步的操作可以通过这些同步对象来同步块内线程,或者是块之间线程的完成的状态(synchronize the completion of the operation)。我们可以显式管理这些同步对象,或者通过库调用进行隐式管理。
关于同步屏障barrier,可以参考这篇文章了解一下并发模型。其目的是为了在并发的线程之间实现同步的操作。
编程接口
CUDA的编译工作流
GPU执行的Kernel方法我们可以用C++来写,也可以用PTX来写。PTX是CUDA指令集架构,相比C++是low-level的编程语言,有一点像汇编。不管用哪种方式编写Kernel,最终都需要通过nvcc来编译成二进制代码,才能执行才GPU上,这一点你在工程属性配置中也能看到。nvcc,即NVIDIA Compiler Collection,也是一套编译工具集。对一个CUDA Program来说,具体的编译工作流是这样的:
1. Offline Compilation离线编译
- 因为一个源文件一般是包括了CPU与GPU端代码的混合,所以nvcc会在这一阶段先将
device code与host code分开。 - 然后先编译
device code,生成一个汇编形式的文件assembly form,即PTX code,这一步类似于gcc -s。你也可以控制直接生成二进制形式的对象文件,在CUDA中被叫做cubin object。 device code编译好后,所有的定义的Kernel方法都被编译成了PTX code或者cubin object,然后nvcc会将<<<...>>>这样的语法直接替换为CUDA Runtime的一些函数调用,来装载和启动我们已经编译好的Kernel。- 最后nvcc会调用
host compiler来编译剩余的host code。你也可以控制直接输出还是C++代码的host code,再使用别的编译工具来编译。
2. Just-in-Time Compilation即时编译
- 即时编译发生在程序运行时,基于离线编译的结果,GPU驱动程序会将程序所装载的
PTX code进一步编译成二进制代码。虽然这会增加程序加载的耗时,但是其相应的给应用程序带来了最新GPU驱动所提供的任何编译上的改进。这也是当下编译的应用程序能够在未来诞生的GPU设备上继续跑下去的唯一方法。英伟达使用这种设计来做CUDA程序的向上兼容。 - 因为每次调用
Kernel都是调用CUDA Runtime的一些方法来装载和启动这些PTX code,为了避免频繁的即时编译,GPU驱动层也会对这些编译结果进行缓存。当你的GPU驱动升级后,这些缓存也会全部失效,需要使用新的驱动重新编译。

