性能优化,最重要和最花心思的是如何发现问题和定位问题,解决反而是比较容易的
项目经历
从2019年4月开始以引擎身份进入项目组开始,我可以说是从头到尾参与了H2项目的开发。从最开始的demo预研,立项讨论,再到开始开发2D的场景编辑器,到实现项目的基础模块和功能,包括性能问题的排查与优化,一直到2020年6月份最后收尾,这持续一年多的项目经验让我收获颇丰,也有了对游戏开发有了初步的理解。
在开始聊正文之前,先简单介绍一下项目性质。H2是基于Laya引擎开发的多平台H5 RPG手游,以包括Android/iOS Native,Android/iOS WebView,Chrome/Safari浏览器,微信/QQ小游戏等多种形式上线多个平台。这也是H5的优势:一次开发,多端体验 ,不过适配开发的内容也不少。
游戏的内容与形式就不提了,属于国漫IP衍生产品,玩法是典型的国内RPG风格,本文单纯从技术上分享我关于游戏性能优化的一些思考。
我参与了哪些性能相关的内容
资源规格的设立和约定
项目初期对美术资源规格的把控从基础层面决定了后期性能的表现与优化难度。而这除了通过demo进行粗略的性能验证以外,也需要大量的项目经验辅佐判断。我入组时,引擎这边预研的demo已经跑了起来,虽然只有一个简易的模型和一个2D背景。H2项目是我们第一次使用Laya引擎开发的项目,缺少很多经验和技术的积累。所以在很多不太熟悉的关键点上,需要讨论确立流程。
在项目立项早期,我作为引擎共同参与了包括美术、项目组、策划等决策人员出席的研讨会,会上确立了游戏的基本表现形式,比如是2.5D还是3D,美术资源的规格与游戏精度,比如贴图的分辨率,主角有多少个朝向,动画的类型是序列帧还是骨骼动画,如果是序列帧动画那是要具体多少帧,场景内最多容纳多少怪物等等。

*最终主角动画使用序列帧来实现,UI中人物用骨骼动画来展示*
因为考虑到整体游戏的风格和性能要求,骨骼动画并没有用作主角的展示,只是作为点缀加入到了部分UI之中。
在这个阶段,通过经验选定一些内容的实现方式后还需要根据游戏的需求通过demo测一下基本的性能表现,比如可接受的情况下最多支持多少动画同屏播放。而这些性能测试的表现也间接影响了后续策划对游戏内容的一些规划。
公共图集
图集是最常见的静态合批技术,通过将不同的图片优化合成为一张大图,并记录不同图片的位置大小等索引信息,达到以下效果:
- 合成图集时会去除每张图片周围的空白区域,加上可以在整体上实施各种优化算法,合成图集后可以大大减少游戏包体和内存占用
- 多个
Sprite如果渲染的是来自同一张图集的图片时,这些Sprite可以使用同一个渲染批次来处理,大大减少CPU的运算时间,提高运行效率。
合并渲染批次,是实时渲染里很多CPU优化技术的核心思路。合并渲染批次,相当于减少drawcall,即调用DrawIndexedPrimitive(DirectX)或者glDrawElements(OpenGL)的次数。主要针对的是CPU在两次drawcall之间的渲染状态改变比如切换到使用一个不同的材质,会导致显卡驱动中进行属于资源密集型resource-intensive的一致性验证和转换的工作,而这部分性能开销在drawcall数量上去后十分可观。
// drawcall
SetShader("Diffuse");
SetTexture("铁");
DrawPrimitive(DeskVertexBuffer);
// another drawcall
SetShader("VertexLight");
SetTexture("木");
DrawPrimitive(ChairVertexBuffer);
Laya IDE内置了图集打包工具,打包会生成若干张png与一个json格式记录图集信息的atlas文件。一般情况下我们会将一个功能或UI面板中用到的图片打成一个图集来达到减少drawcall的目的,同时我们也会将各个功能通用的一些小图或组件打包成公共图集,持久的加载在内存中,避免对待普通图集时的清理,来减少drawcall数量和提升加载速度。

*图集*

*公共图集*
公共图集的优化效果则取决于各个功能模块的开发者,他们需要将多个功能/模块中通用的图片摘出,加入公共图集进行打包,而非独立打包。同时也需要考虑公共图集的大小和数量,因为长期驻存在内存中意味着内存规模的上升,这需要衡量和取舍。
对象池技术
Object Pool对象池也是极其常见的性能优化技术,针对频繁、反复创建可重用对象的场景有很好的优化效果,比如游戏内的飘字,子弹,可重用的动画组件,场景内的角色怪物等等。对象池与内存池技术原理相似,都是考虑到频繁的内存申请与释放而引起的系统调用带来的性能开销。所以通过回收重用对象避免,能够有一定的性能优化效果。不过优化效果因场景而异,在一些非常简单的使用场景下使用对象池技术反而会导致反向优化。
一般情况下,对象池的工作逻辑时这样的:
- 在初始化阶段,对象池会创建若干同一类型的对象,并初始化一个记录各对象可用状态的表。
- 每次需要创建对象时,改为向池借用一个对象,并且使用者自己做好初始化工作,同时记录表中更新该对象的可用状态。
- 当用完对象需要销毁时,改为向池归还该对象,池则会做好清理和重用的工作,比如调用该对象的构造函数,同时记录表中更新该对象的可用状态。
- 同时池应该也要具备自管理的一些机制,比如:
- 当没有可用对象时,需要拓展池的规模,保证能够正常的借出可用对象;
- 而在一个对象创建高峰过后,也应该有一些策略来缩小池的大小,销毁池内的一些对象,即控制池规模在一定范围内;
- 如果支持多线程,则在借出对象时需要做一些同步支持工作;
根据需求不同,池的规模大小也不同,如果池的规模过大,在初始化批量创建或者缩小池的批量销毁时,可能会导致单帧Update的耗时过高,引起帧数波峰变化,这种情况下可以通过摊帧解决。
// 可供参考的对象池类结构
export class ObjectPool{
protected pool_type: PoolType = null; // 池类型
protected obj_class: any = null; // 对象类型
protected constructor_args: any = null; // 传入构造器的参数
protected max_obj_id: number = 0; // 最大对象id,从1开始
protected obj_map: any = {}; // 对象池: {pool_obj_id, object}
protected obj_cur_count: number = 0; // 对象池当前数量
protected idle_key_map: any = {}; // 记录对象信息空闲池: {pool_obj_id, boolean}
protected idle_key_cur_count: number = 0; // 空闲池当前数量
protected retain_threshold: number = 0; // 池清理的下阈值: 池中对象数量<=此值, 则停止清理
protected shrink_threshold: number = 0; // 池清理的上阈值: 池中对象数量>=此值, 则可以清理
protected shrink_check_time: number = 0; // 池清理的间隔时间
protected delay_create_flag: boolean = false; // 是否摊帧创建
protected inited: boolean = false;
protected pool_id: number = null; // 池ID
protected next_shrink_interval: number = 0; // 下次池清理的剩余时间
// 构造对象池,传入对象类型,对象构造时的参数,池规模大小等信息
constructor() {...}
// 自动管理与摊帧创建
public Update(): void {...}
// 借出对象,同时具备拓展池规模的功能
public RentObject(): any {...}
// 归还对象,同时检查是否需要缩小池规模
public GiveBackObject(): void {...}
// 真正创建一个对象
protected CreateOneObject(): any {...}
// 真正销毁一个对象
protected DestroyObject(): void {...}
// 缩小池规模
protected Shrink(): void {...}
// 一些统计、profile接口
...
}
CPU耗时分析工具与可视化性能报告
在一些游戏场景或内容有肉眼可见的卡顿,或者平均帧数不达标,或者需要在开发的不同阶段对性能表现进行把控的时候,性能的量化和可视化工具就是一个非常重要的东西了。最常见的应该就是对CPU耗时的分析工具了,而这个大部分引擎和IDE都做了支持,比如Unity Profile,可以详细到函数的执行栈和具体某个函数的执行时间。
Laya作为H5游戏引擎,我们可以使用Chrome的DevTool中的Performance来分析游戏的CPU耗时,同样可以看到每一帧的执行栈和具体耗时。除此之外,在JavaScript执行的过程中,我们还可以通过performance API对一些我们关注的执行过程进行耗时测量和标记。随后在DevTool记录Performance Record过程中,我们标记和测量的结果都会显示在Timeline瀑布图中的Timings栏,我们还可以在Event栏中对这些标记进行检索和排序。
performance.mark("A")
performance.mark("A_End")
performance.measure("A_Result", "A", "A_End")
对此我们可以有很多应用,比如对所有协议的收发阶段进行标记和测量,并在性能报告中对协议的耗时进行检索和排序,就能够一眼看出哪些协议耗时过高或次数过多需要优化了。
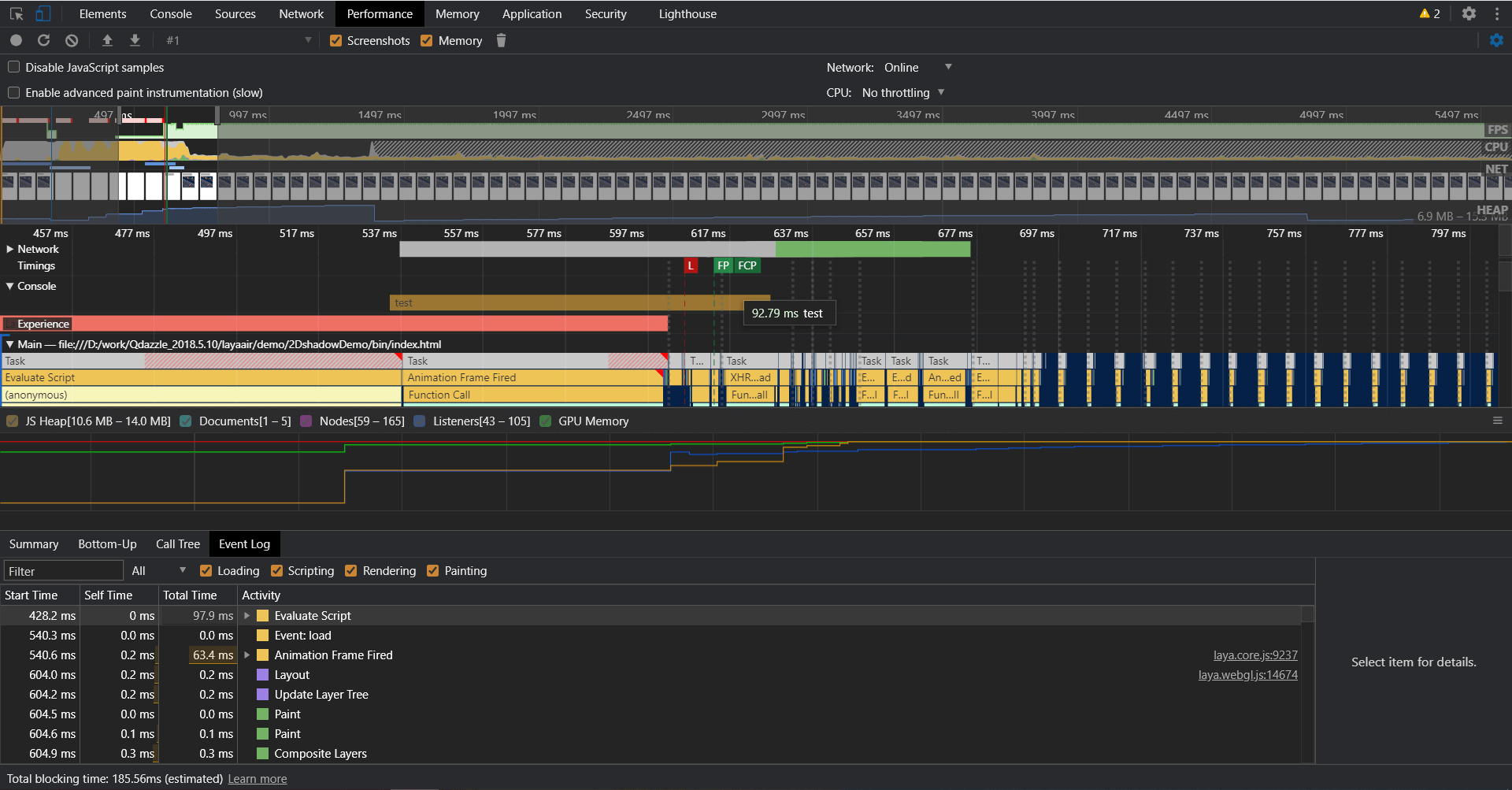
*Chrome Timeline瀑布图*
但是在使用Chrome的DevTool的过程中,我发现Chrome的瀑布流图表对异步过程的标记和测量存在bug。比如在需要测量的两个标记中如果存在其他未闭合的标记,虽然瀑布流的Timings栏会有记录,但是在Event栏却检索不到该记录,也无法根据耗时排序了。这个bug已经提交给了crbug.com。但是至今还没修复,可能是和数据记录识别的方式有关系。
performance.mark("A")
performance.mark("B")
performance.mark("A_End")
performance.mark("B_End")
performance.measure("A_Result", "A", "A_End")
performance.measure("B_Result", "B", "B_End")
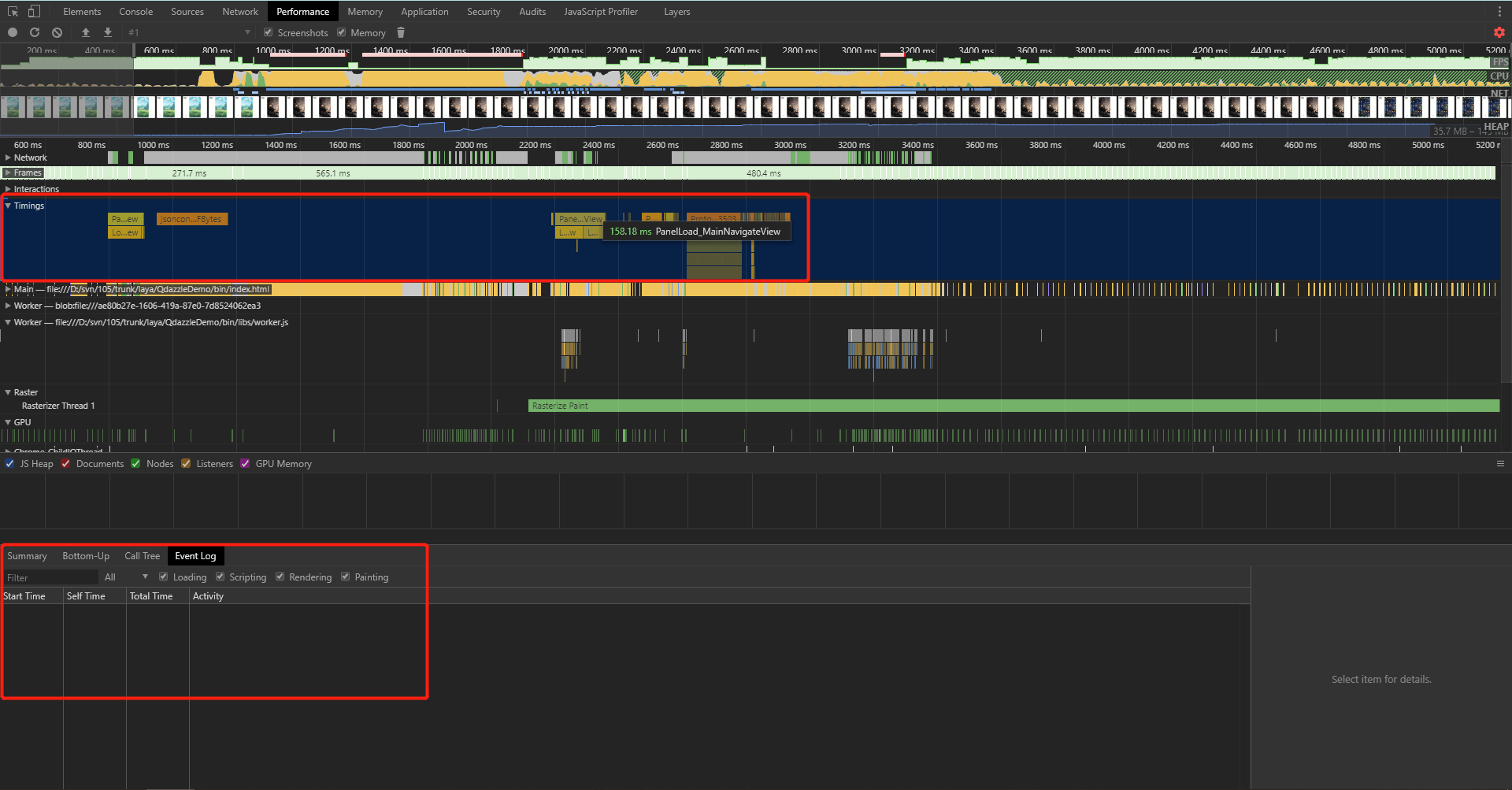
*Chrome Timeline瀑布图无法识别记录*
当然
performanceAPI现阶段并没有被完全支持,在一些环境中(比如微信小游戏,Laya Native及Safari),你可以考虑改用console.time与console.timeEnd来包裹一段执行过程,除了在console控制台输出计时外,记录也会显示在DevTool-Performance瀑布流-Console栏中。或者你也可以封装一个profile工具,判断不同环境用不同的实现,或者空调用。
值得注意的是,尽管Chrome自带的Performance的瀑布流图表已经十分详尽,但是因为记录的内容太多,导致记录本身耗时(虽然可以关闭一些无关的记录选项,比如不关注执行栈时可以disable JavaScript sample),且加载性能数据也非常耗时。实际上做游戏Profile时我们关心的其实只是很小的一部分,比如每个模块的耗时分布,每个协议的耗时,所以一般情况下还是需要自己做一些额外的工作,比如数据的筛选与可视化报告。
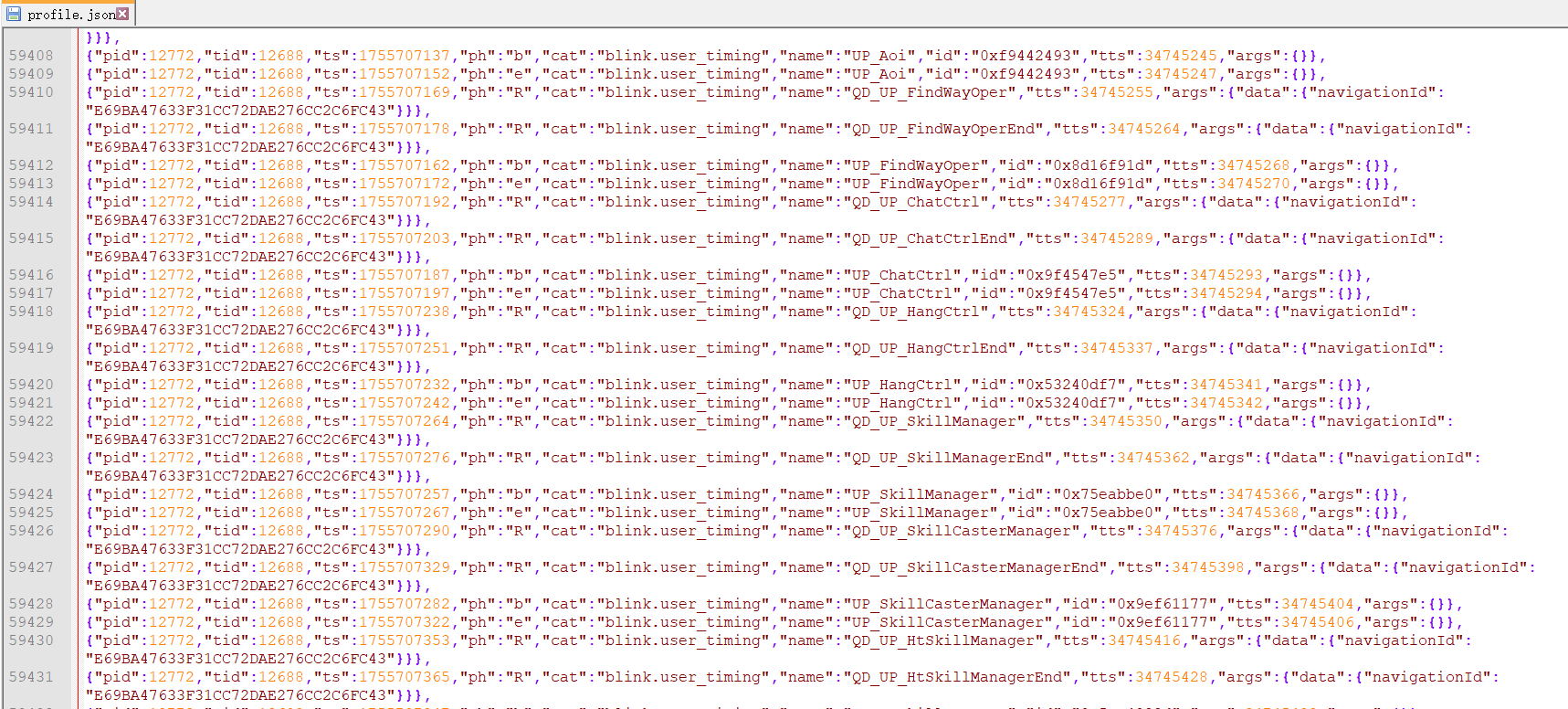
*Chrome 性能数据记录的格式*
在JavaScript中使用performance或console进行标记,并通过DevTool - Performance - Record 产生性能数据后,通过观察输出的JSON数据格式,我们可以找到标记的一些数据特征,通过脚本筛选出来进行计算处理,输出成每个事件的耗时记录。再通过ECharts工具绘制成图表,根据不同的需要输出不同的可视化报告。形成自动化流程后,每个开发阶段都能对游戏的性能有一个合理的把控了。
*数据处理与可视化工具脚本*
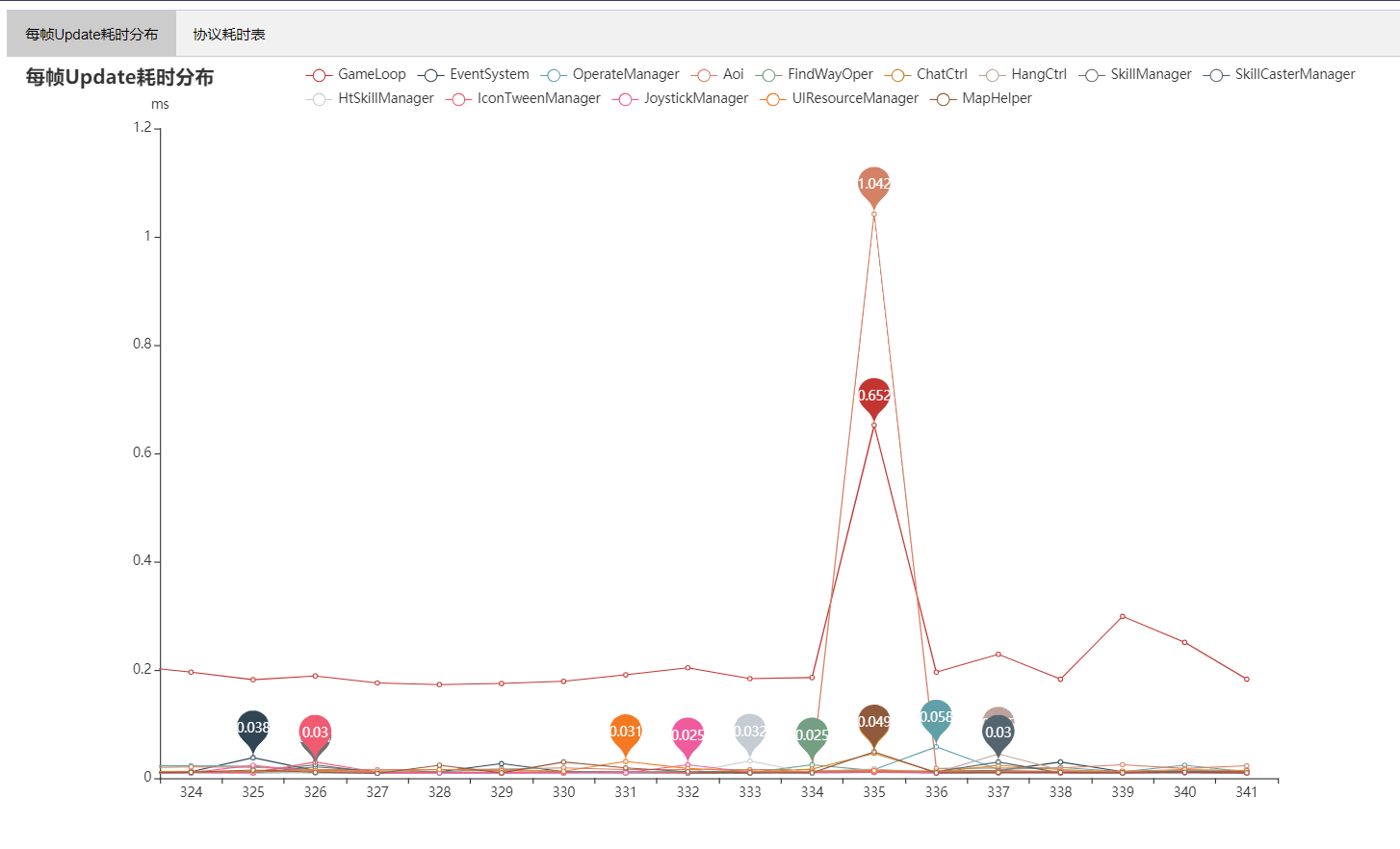
*每帧Update耗时分析报告*
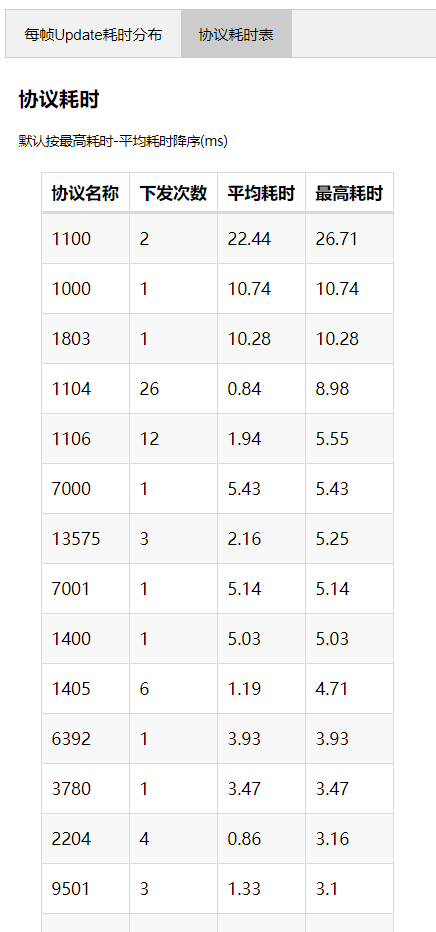
*协议耗时报告*
UI打开速度的运行时监测
UI打开速度是衡量UI性能的一个重要指标,为此我们做了一些相关的工作,用来收集那些需要优化的UI面板以及加载不同阶段的耗时信息。因为UI面板的打开关闭统一抽象成了一个基类,我们可以很方便的加入不同阶段的计时操作,并且只在内部测试环境下开启。
从创建一个UI面板开始计时,到显示出UI面板时停止,中间依次记录UI打开的若干阶段的耗时:
- 加载资源阶段,包括下载时间,队列中的等待时间,图片解析的时间
- UI面板在显示前自身的逻辑执行阶段
- 绑定监听事件阶段
- 显示后UI面板的一些逻辑执行阶段
Laya的资源加载并不会提供详细的计时信息,所以我们需要在
Laya.Loader类中自行记录加载各阶段的耗时,这个需要对laya.core.js进行一定的拓展,这里就不展开了。
我们认为一个面板的打开耗时超过 400ms 即需要优化(只考虑主观感受,不考虑网络环境和设备因素)。当每次打开检查耗时超过400ms时,信息会在本地被收集,除了在日志中打印,也会被上报到管理后台收集。在后台能看到不同设备上的UI打开速度超时报告,一般来说超过400ms打开速度的UI都应该进入待优化列表。
而具体需要优化的点则可以根据不同阶段的耗时来具体针对性排查和优化:
- 比如加载慢,具体是哪个阶段慢?如果是等待时间长,则可能是一个UI所需资源数量过多,导致加载中存在等待的问题
- 如果是下载时间长则考虑图片是否可以压缩,有损还是无损,有损的话可以接受怎样的精度?
- 如果是具体逻辑执行阶段的明显耗时则根据具体代码来进行优化,比如对逻辑重的部分进行摊帧执行。
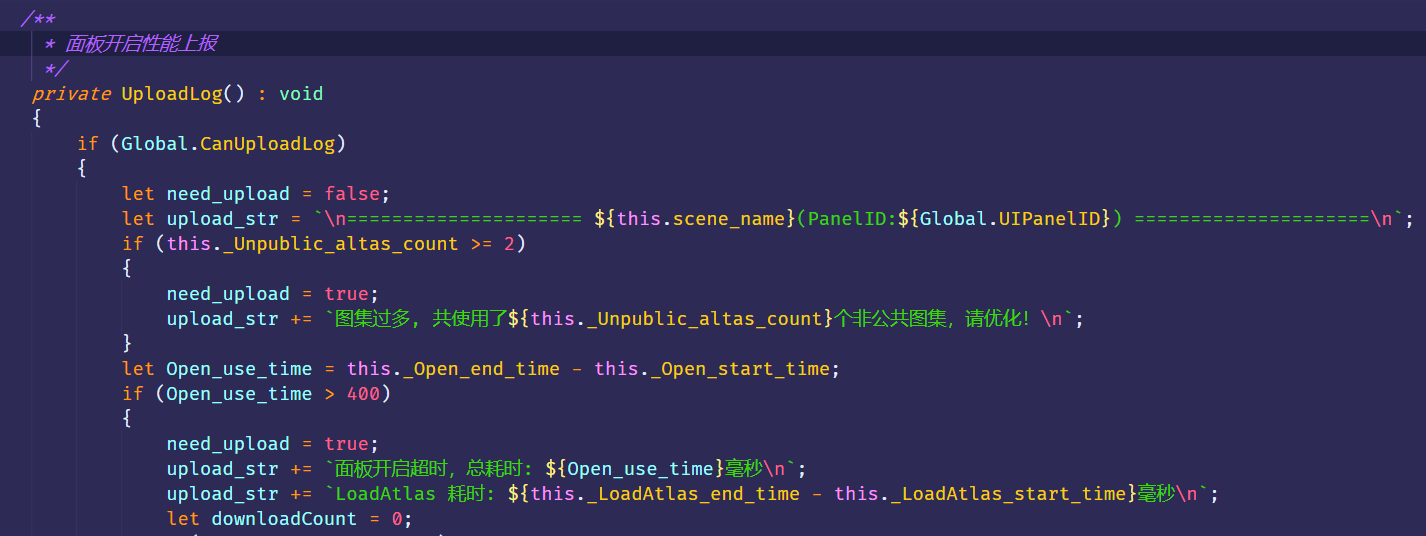
*UI打开速度监测和收集的部分代码*
静态资源标准检查工具的实现
上面提到UI打开速度和面板所依赖的资源规格以及资源数量有较大关系,所以需要对每个UI面板制作时用到的资源进行把控和监测。
值得一提的是,在上线微信小游戏做适配工作时我们也发现,部分UI贴图规格竟然超过了 2048x2048 导致纹理报错,而立项时我们和美术协商的贴图规格是最大 1024x1024 。
所以说尽管在立项时就决定了美术产出的规格和精度,但是因为策划或美术的部分需求和创造力表现,或者是人员流动等其他原因,实际执行起来往往会出现执行出格或不到位的问题。
在推进游戏开发进度的过程中,就像需要code lint来保证代码的规范性一样,必须存在针对其他方面的静态检测工具或脚本来保证一些标准的落地执行。
因此我写了一些简单的python脚本,用来扫描游戏内的UI配置、图集以及实际资源规格,来判断是否制作出了超规格的UI面板。项目组根据这些报告,自行定夺是否优化。而优化完成后,再次执行工具,扫描对比后便能看到问题是否依然存在。
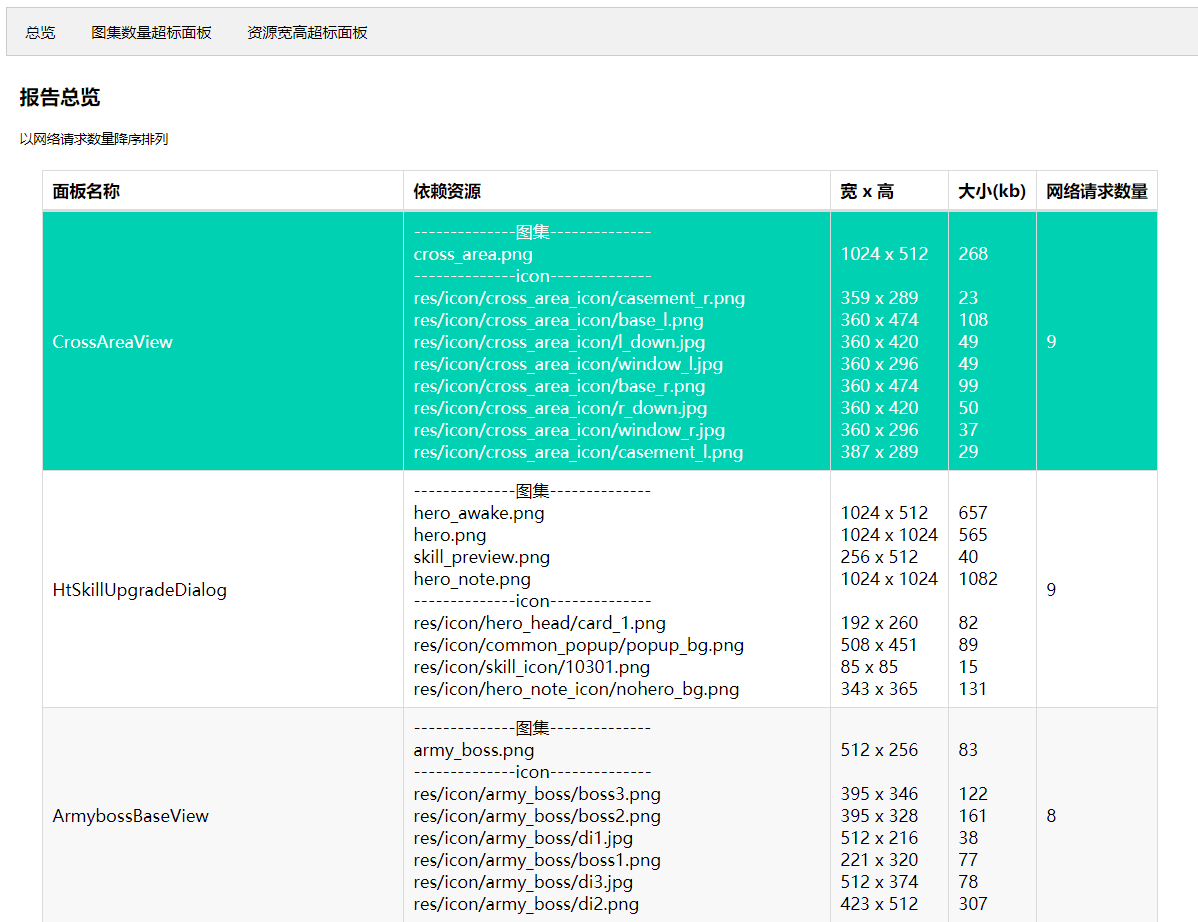
*UI静态检测报告*
同理也需要对特效、模型等进行扫描。其实没有任何技术难度可言,只是通过这样的简易自动化工具,便能快速发现一些问题,而不需要等待问题暴露时再去通过排查来定位。
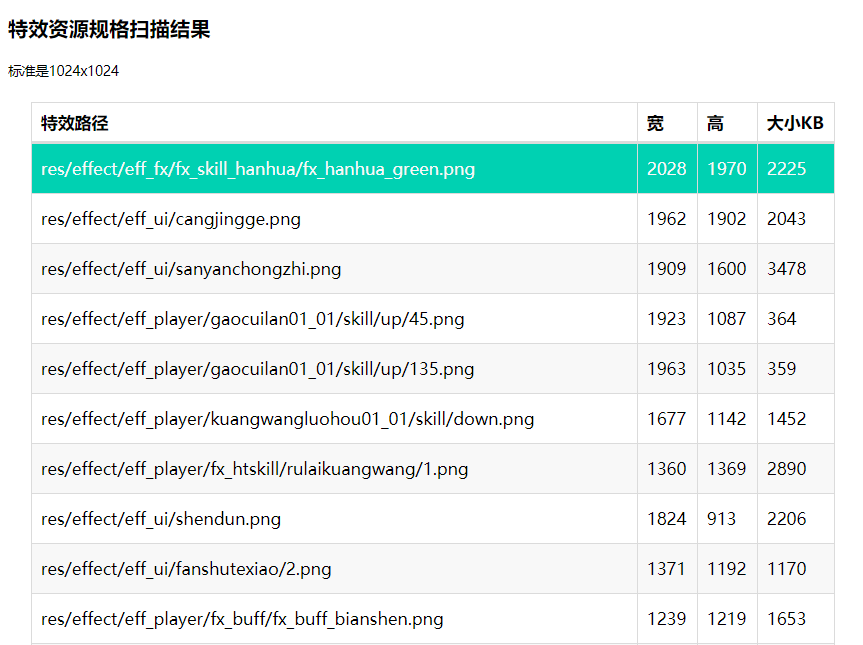
*特效静态检测报告*
内存规模分析与内存泄漏排查
内存的稳定性直接影响了游戏的稳定性,可以从下面三个角度来看:
1.内存泄漏
当游戏使用的内存Proportional Set Size即实际使用的物理内存值(包括按比例计算系统共享库使用的内存)达到系统设定的最大值时,操作系统会强制杀死该进程,并报出Out Of Memory的错误,这个报错在一些线上项目的Bugly上经常能看到。如果游戏出现比较频繁的内存泄漏,哪怕每次泄漏分配了很小块的内存但是又没有被释放,也很可能运行三十分钟后内存就爬升到系统设定的阈值因而崩溃。
不同内存的机器和不同系统其应用可使用的内存上限不一样,比如2GB内存的iOS机器允许应用使用的最大内存是1395MB,而4GB的iOS设备则允许到2GB左右,8GB的安卓机器则远大于此。iOS允许应用可使用最大内存值可以参考这里。在iOS13 SDK中,Apple还提供了相关的API来查询设备允许的最大内存值,安卓也有对应的查询方法:
// 要求iOS 13.0
#import <os/proc.h>
extern size_t os_proc_available_memory(void);
+ (CGFloat)availableSizeOfMemory {
if (@available(iOS 13.0, *)) {
return os_proc_available_memory() / 1024.0 / 1024.0;
}
}
// 要求Android API 1+
private long getMemoryThreshold() {
ActivityManager activityManager = (ActivityManager) this.getSystemService(ACTIVITY_SERVICE);
ActivityManager.MemoryInfo memoryInfo = new ActivityManager.MemoryInfo();
activityManager.getMemoryInfo(memoryInfo);
return memoryInfo.threshold;
}
一般来说,游戏内内存泄漏的发生场景可能是以下几种,这里只讨论具有现代化的垃圾回收器的语言。需要自己管理内存的C/C++暂时不讨论:
- 加载的资源用完后没有及时清理,长期占用内存。比如
Laya引擎中是需要调用Laya.loader.clearRes来清理资源释放内存,否则Laya.Loader.loadedMap中会一直存在对该资源的引用,其占用的内存也不会被垃圾回收器回收。而在我们排查过程中发现许多业务代码中就存在这些问题,一些副本或面板退出后的特效/icon等资源没有被及时清理。 - 存在全局或静态变量引用而导致无法被垃圾回收的情况。同上,因为对象至始至终都有引用,所以无法被垃圾回收器回收,从而导致泄漏。这需要对模块业务代码进行筛查,在有使用全局或静态变量来记录一些临时对象的地方要谨慎对待。
- 错误使用引擎代码而引起的内存无法回收。开发过程中几乎不可能避免封装,游戏引擎也是高度封装的一种。错误的使用别人封装的模块往往也会导致内存泄漏。像
Laya这样有源码的则需要彻读源码了解具体的实现,没有源码的封装则需要详尽阅读模块说明,做到尽可能的符合规范。H2项目就出现因为错误使用Socket模块而导致Socket连接断开时字节buffer没有被清理。
那么具体如何排查内存泄漏?这就需要一些辅助的工具来发现问题。
引擎工具
首先是借助引擎内部的一些debug工具或profile工具来检查无用资源或引擎对象的清理是否正常。如果自己封装了一个管理类,则还要测试管理类的加载和清理策略是否正确,清理策略是否合理。比如H2项目中,我写了一个实时展示Laya引擎可视对象的数量的统计组件,用来检查游戏内各个功能或场景是否存在引擎对象泄漏的问题。因为项目中的所有可视对象都继承于Laya的Node类,所以可以拿到子类的name,再通过hook其构造和销毁函数统计子对象的数量变化。
// 引擎自定义对像统计CustomStat.ts
public static getClassName(tar)
{
if ((typeof tar == 'function')) return tar.name;
return tar["constructor"].name;
}
...
// Hook Part
let CreatedFunc = (sp) =>
{
let class_name = CustomStat.getClassName(sp);
CustomStat.ReportNew(class_name);
}
let DestroyFunc = (sp) =>
{
let class_name = CustomStat.getClassName(sp);
CustomStat.ReportDestroy(class_name);
}
this.Hook(laya.display.Node, "call", CreatedFunc);
this.Hook(laya.display.Node, "destroy", DestroyFunc);
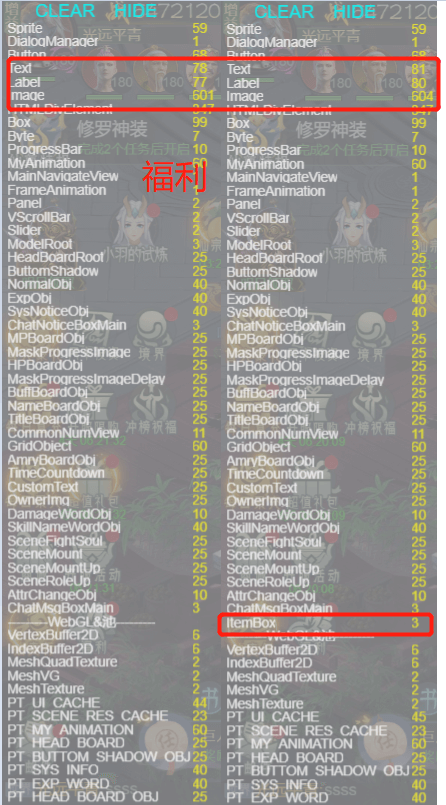
*引擎对象统计*
我们通过反复打开关闭某一功能或进出某场景,再对比统计数量就能看到一些组件的泄漏。这是统计监测引擎对象数量变化的组件,同样我们需要实时能够看到一些贴图资源是否真的从Laya.Loader.loadedMap中移除并真正的释放内存。如果是通过控制台console.log(Laya.Loader.loadedMap)观察也可以,但是太过麻烦,并且有时候加载的资源数量达到几百上千条,则会卡控制台。为了解决这个问题,我们拓展了Laya的DebugPanel进行展示,并且通过资源路径来区分不同的资源种类,并提供一些预估值来计算其占用的内存大小。
Laya引擎本身在laya.debugtool.js中写了一些用于debug和profile的功能组件,但是不知道为什么官网并没有给出使用说明,可能废弃了大部分功能,只保留了一个DebugPanel。并且还对DebugPanel的一些代码进行了base64加密,给最初拓展该组件带来了一定的麻烦。
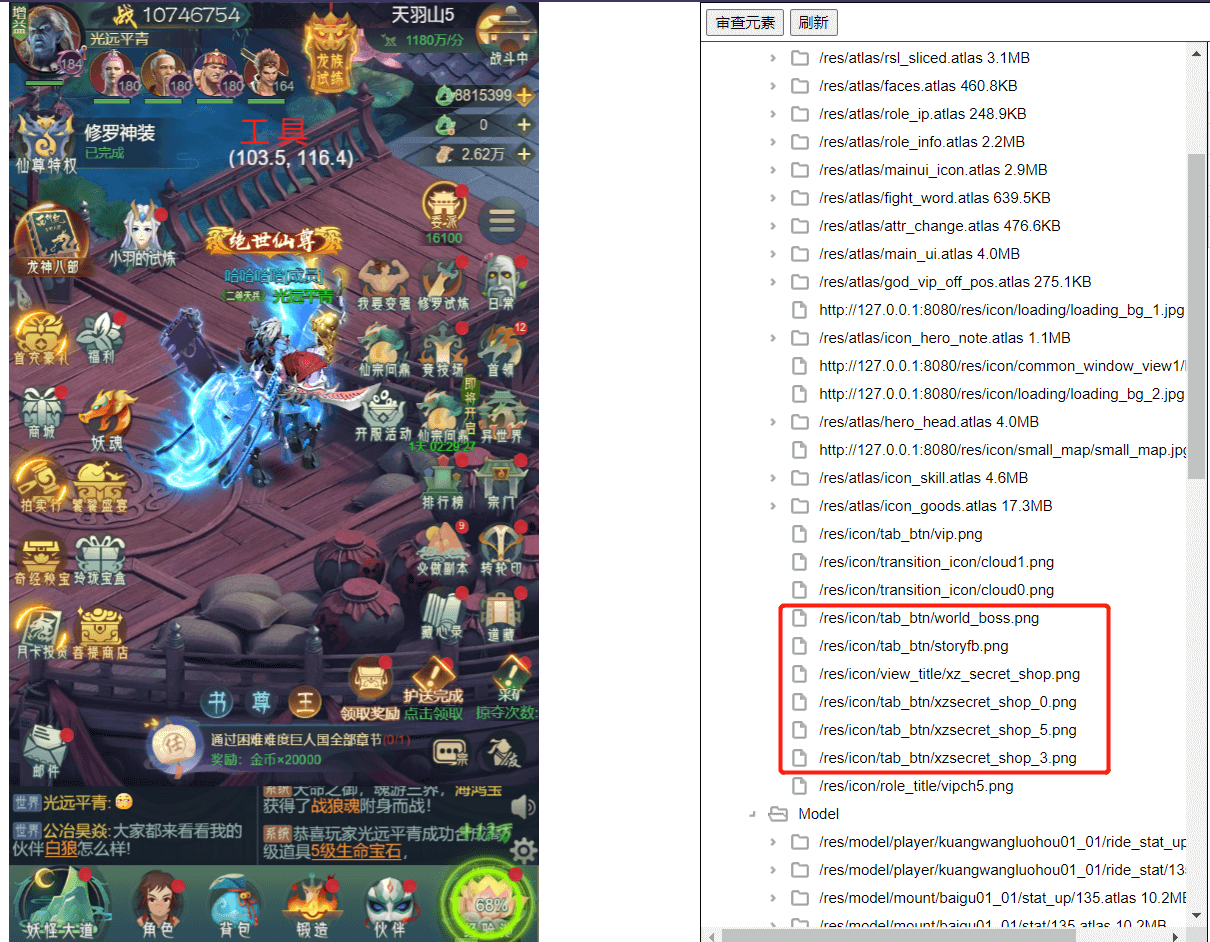
*DebugPanel拓展*
H2项目中我使用这两个工具在最后性能收尾阶段跑完了游戏内所有40个功能以及20个副本,发现了数十个泄漏以及代码上的问题并修复。从这个结果上看,引擎层面的工具对游戏的稳定性而言是十分重要的。
设备内存
以上是游戏引擎层面的工具,在设备/系统方面我们也需要一些工具来确定内存的整体规模和判断是否有内存泄漏的问题。比如在iOS设备上使用Xcode调试查看应用使用的内存,CPU,网络,甚至耗电情况和原因,当然Android Studio也基本有同样的功能。这些IDE除了提供查看实时的内存规模变化的功能外,还提供了一些专门检测Leaks即内存泄漏的功能。
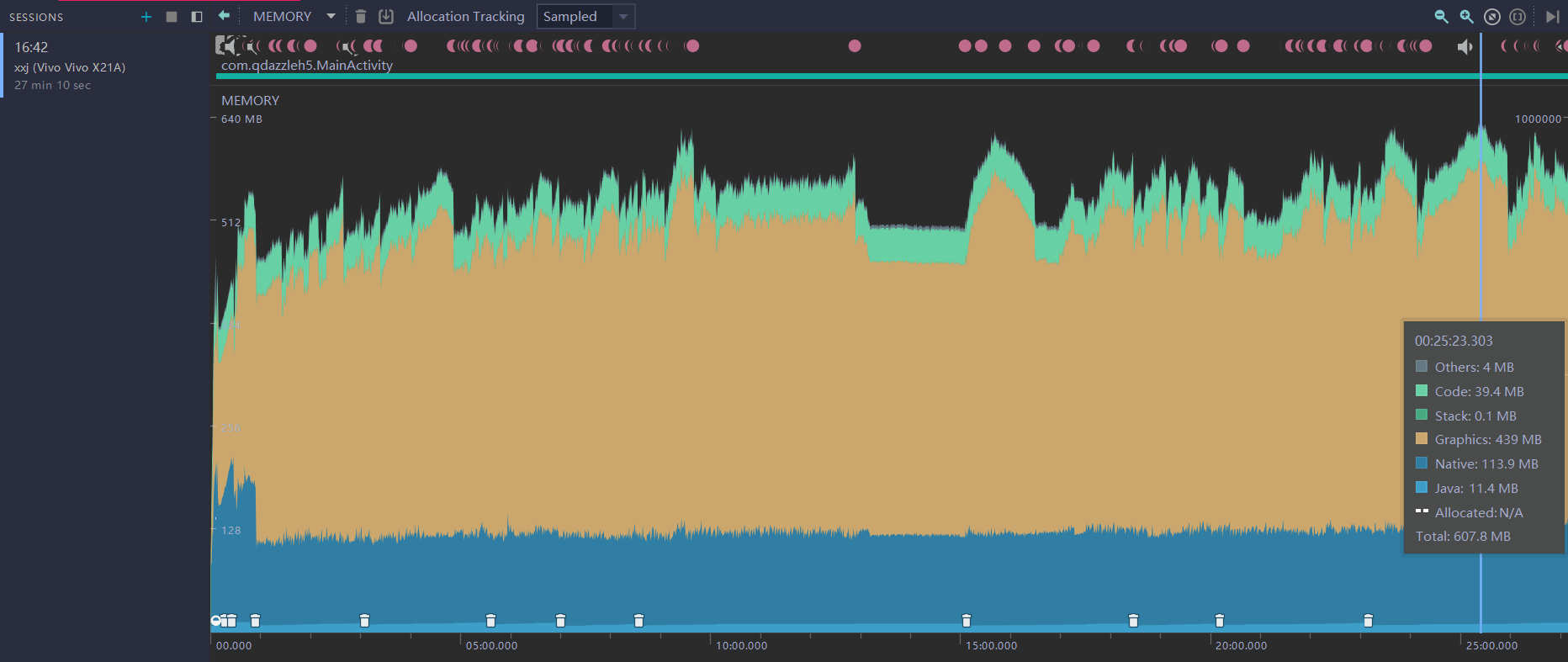
*使用Android Studio查看应用使用的内存*
和引擎层面排查泄漏同理,通过观察反复进出同一场景/打开同一功能引起的内存规模的波动是否正常,一般就能判断游戏内是否存在内存泄漏问题。
H2项目也因此解决了若干个因为错误使用了Laya引擎的动态合批功能而引起的内存暴涨导致的OOM问题,修复后将项目内存规模稳定到了Android设备测试环境下400-600MB区间。
因为项目是多平台发行的,除了传统的iOS/Android设备环境外,还有Chrome以及小游戏环境,同样需要对应的Profile工具来查看内存情况。微信小游戏环境下可以使用安卓设备,运行时打开Profile模式,便可以在右上角看到内存信息,机制与安卓同理。Chrome则可以通过Shift + Del打开浏览器的任务管理器,查看页面内存使用情况。如果觉得表格数字不够直观,你也可以使用 GraphProcess 这款Chrome插件来查看内存变化情况。
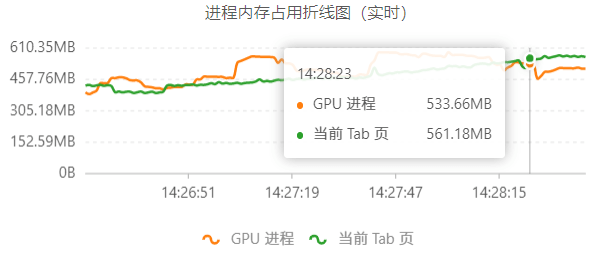
*使用GraphProcess查看Chrome内存波动*
2.内存规模
而除了内存泄漏方面的问题,游戏内整体的内存规模也应该控制在合理水平,才能让更多相对低配的机器能够畅玩。一个游戏对相对低配的设备越友好,潜在的玩家数量也会越大,PUBG除外。
PUBG刚出来的那会,内存管理就做的十分差劲。许多网吧8GB的机器玩起来十分吃力,并且游戏应该存在较为明显的内存泄漏问题,每跳三次伞基本就会发生一次闪退。虽然这样的内存管理拉动了内存条价格飞涨和玩家机器配置的飞升,但是这样的游戏体验也颇为大家诟病。
在H2项目中,我们就在优化阶段将小游戏环境下的内存规模优化了400MB左右,使得iPhone7这样的2GB的设备能够正常运行,达到了我们的目标,而在优化前2GB的iOS设备基本只能跑十分钟主线就会被微信杀掉。
在优化游戏整体的内存规模时,需要对优化目标有一个选择。虽然大家都很想要竭尽全力的做好每一处细节使得性能最优,但是出于工作量考量,质量与性能取舍等原因,一个项目不能无限优化。一个针对具体项目的性能期望则是优化收束的终点。比如H2项目中,我们希望内存优化可以使得iOS 2GB设备与Android 4GB设备可以在微信小游戏环境下稳定运行超过2小时。而iOS 1GB的设备(如iPhone6)从优化开始的阶段就已经被放弃,因为1GB的iOS设备应用可使用的内存阈值也只有645MB左右,并且还需要跑在微信的环境下,可使用的内存更少了,对可接受的游戏品质而言是基本无法做到稳定运行的。
3.垃圾回收
内存方面还容易出现的一个问题是垃圾回收即Garbage Collection频率过高,因为现在大部分解释型语言的VM垃圾回收器都是运行在主线程,且或多或少都会引发用户线程暂停执行即Stop The World,哪怕是Lua 5.3的步进式GC,每一次Step都需要暂停主线程执行。而即使是JavaScript V8引擎做了大量多线程优化后,一次Major GC也要10ms左右。所以过于频繁的GC会导致部分帧渲染耗时飙升,从而造成掉帧卡顿。
因此在Profile CPU耗时时也需要关注GC的次数是否过于频繁而影响到了性能。如果GC次数过多,则需要进一步判断是否需要使用池技术来减少真实的内存分配和回收的过程。
那具体怎么做来优化内存规模呢?这个之后在这里讲。
微信小游戏卡顿问题的定位
因为这是公司第一款上线微信小游戏的产品,在这方面还没有技术积累。所以小游戏这方面的所有开发Leader全权交给了我去研究和实现。在调通了Laya发布到微信小游戏环境后,我需要做一些适配工作,这个写在了这篇文章中。除此之外还写了一个登陆支付的SDK客户端,以及开发一些其他的平台性质的需求比如首屏Loading图加载和播放视频。当然我们也遇到了一些其他的性能问题:
- 5s内收到2次
Memory Warning导致的OOM被杀问题。这个我通过优化内存规模,排查内存泄漏,调整更为保守的内存Cache策略解决了。 - 一些贴图超2048导致无法显示,以及一些贴图过高精度导致加载慢,这些通过写的静态扫描工具去排查逐一解决。
Laya引擎提供的适配层laya.wxmini.js中存在的一些bug,比如短时间多次请求同一音效资源Cache未拦截后续请求,导致短时间大量播放音效而卡顿的问题,这个通过修复引擎层解决了。- 小游戏环境下因为性能表现受限,需要限制一些游戏表现和行为。如除主角外其他模型均使用圆影阴影而非实时阴影,限制角色升级这类统计事件上报的频率等。这些通过判断环境做适配区分解决。
- 音效资源比特率未统一,部分音效比特率过高,解码时引起内存大幅度扰动。这个通过统一压缩音效资源比特率解决。
- 如果使用
Laya的缓存策略的同时又使用微信APILogManager来记录本地日志文件,则会因为二者共享50MB的用户空间而导致Laya自己计算的可使用缓存空间大小错误,因而在用尽本地用户空间时,无法正确的缓存新下载的文件,这个通过改写laya.wxmini.js中的最大缓存空间为45MB即可,因为LogManager记录的本地日志文件最大为5MB。
值得一提的是排查主流程某个性能问题的经历。表现是游戏内主流程跑到某个阶段,必现的加载缓慢,游戏卡顿的问题。我首先确定了使用的资源已经经过压缩,然后通过在引擎层对加载各阶段的耗时统计,以及近N次加载耗时的平均发现了卡顿时的异样表现,最终定位到了原因是在Loader队列中等待的时间过长。
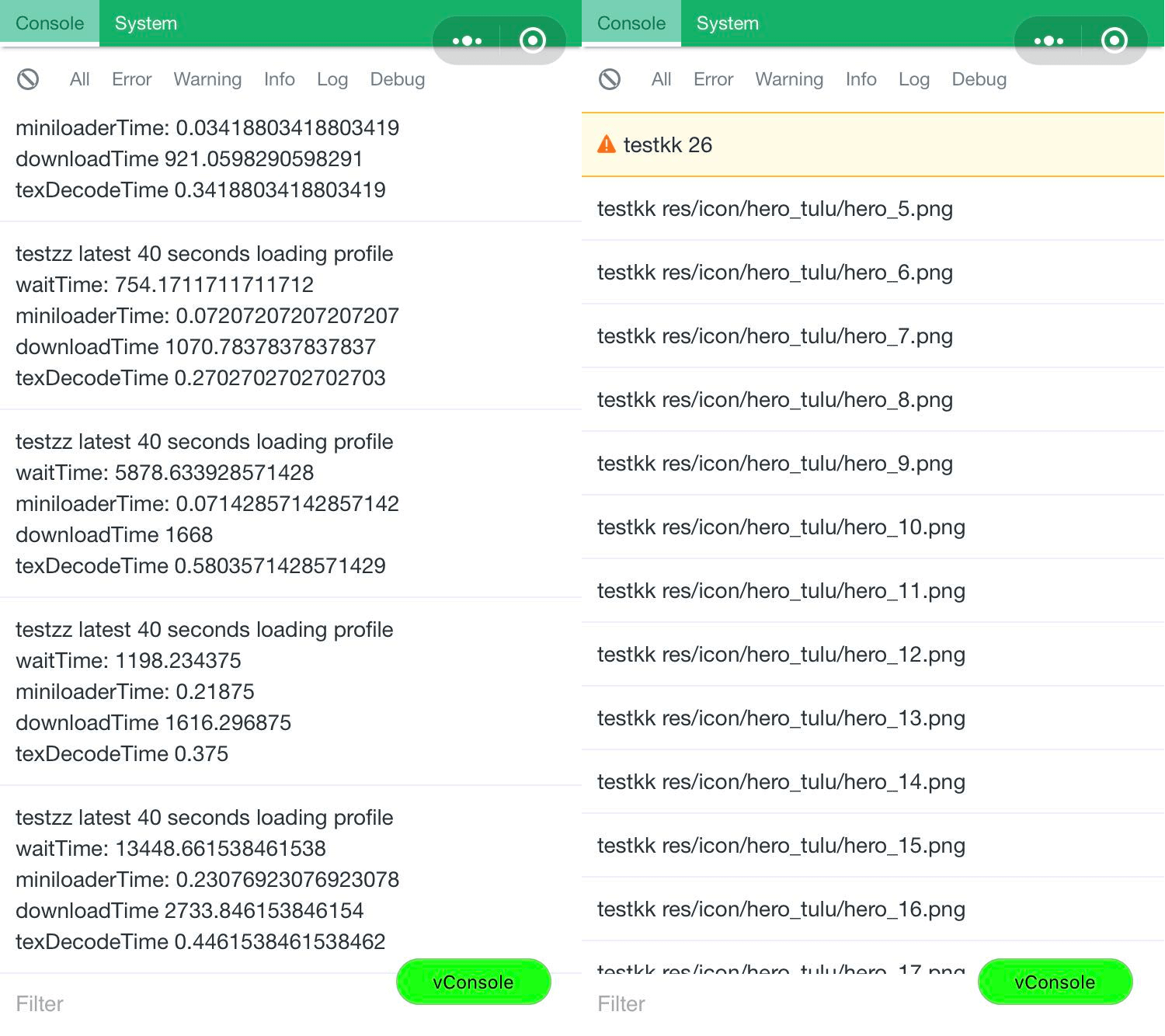 *资源加载各阶段的耗时统计与问题定位*
*资源加载各阶段的耗时统计与问题定位*
通过打印等待队列长度及其内容时发现,卡顿时等待队列最长去到26个待加载资源。而这是因为打开了某个制作未被优化而依赖了十余个icon的UI,或者游戏内主流程在某个阶段进行频繁的场景切换,而大量场景地块、怪物、NPC乃至角色的部分动画都因为Cache策略的调整而未被缓存到内存中,需要重新下载,导致待加载队列过长,从而导致大幅度的下载延时。这一点在其他端没有测出来,但是在小游戏环境下表现颇为明显。
发现问题后,我们通过将角色全部动画缓存在小游戏的50MB用户空间,使得切换场景时不用下载,以及调整了地块等其他资源的Cache时间,使得其短期内加载更频繁命中缓存,并且优化了有问题的UI面板,使其依赖资源数量大幅度减少,解决了爆表的等待队列问题。
微信小游戏缓存50MB策略优化
令人欣慰的是,在作者写本文时,微信小游戏本地文件系统最大支持容量已经增加到了200MB,不再拮据,大部分H5游戏兴许也不再需要特意针对优化其缓存策略了。
微信小游戏的文件系统中,本地缓存文件与本地用户文件共享50MB的最大容量,可以参考官方的小游戏基础能力说明。
- 首先所有的云端游戏资源通过
wx.downloadFile下载到本地临时空间,并会返回一个临时文件路径,你可以通过readFile直接读取加载。该空间不限大小,但是下次冷启动时大概率会被清理,所以没办法用来做持续缓存策略。 - 如果需要缓存该资源,则可以通过
FileSystemManager.saveFile接口移动文件到本地缓存空间,本地缓存文件只有在代码包被清理的时会被清理,也就是用户常按删除小程序的时候。该空间与本地用户空间共享50MB大小限制。 - 本地用户空间则是对应
wx.env.USER_DATA_PATH目录,开发者对该空间拥有完全的读写权限,可以通过其他文件接口如FileSystemManager.writeFile创建文件并写入内容等。该空间与本地缓存空间也共享50MB大小,并且也只有在代码包被清理的时会被清理。
上文提到的微信的日志API
LogManager记录的日志文件则是存放在本地用户空间下,最大占用5MB,挤占了本地缓存空间的大小,才导致了Laya默认的缓存策略计算可用大小判断是否缓存时的错误。
Laya引擎提供的laya.wxmini.js适配层的资源缓存策略是完全在本地用户空间下做的:下载网络资源后,如果属于图片资源或json资源,则拷贝到本地用户空间下作为缓存文件,然后在本地用户空间下读取该文件,同时更新维护一个本地文件layaairfiles.txt来管理缓存的URL与对应文件的路径映射用于下次加载时命中缓存,以及记录可用空间大小用于控制整体缓存大小。每次启动游戏时便会根据该文件来反序列化一个内存对象,而新增缓存文件时则又通过序列化更新该文件。
以上策略都没有问题,问题是当准备缓存的临时文件大小超过了layaairfiles.txt文件中计算出的可用大小后,Laya的默认缓存策略会删除最早进入缓存的一批文件(默认是清理出5MB大小的空间,会根据即将缓存的文件大小调整)来为即将缓存的文件腾出空间。但是因为游戏最早的加载阶段,缓存的全是各功能模块依赖最多的公共图集资源。这一部分资源理应常驻缓存,即使删除了则又会马上下载,并且再走一遍移动到缓存空间的过程,且不说这样的操作直接影响资源加载响应的速度,频繁的文件IO也会带来更高的性能开销。而事实上,每当缓存空间满50MB后默认清理5MB空间,根据我们项目的资源加载频率,我们测试平均 10s 不到便又会出现满50MB的情况。游戏内观察也出现了明显的加载响应慢的问题。
//缓存过滤,只缓存公共图集、UI icon与音效
MiniFileMgr.cacheFilter=new RegExp("(/atlas/|/icon/|/sound/)");
...
//符合要求的才进入缓存,缓存满后不再进行缓存
if((MiniAdpter.autoCacheFile || isSaveFile)&& readyUrl.indexOf(".php")==-1
&& MiniFileMgr.cacheFilter.test(readyUrl) && !MiniAdpter.reachMemLimit)
MiniFileMgr.copyFile(data.tempFilePath,readyUrl,callBack,"",isAutoClear);
为此我设计了一个针对性的缓存策略,根据请求的URL通过正则匹配,只针对公共图集,UI icon,音效这类频繁使用的资源进行缓存。即我们对进入缓存的资源进行手动选择,尽量充分利用空间大小,并且屏蔽了清理逻辑,当缓存空间满后,不再将临时文件移入缓存。通过统计Network所有请求中缓存文件http://usr请求的比例,就能计算出缓存命中率。我们发现同样跑完新手流程,调整缓存策略后缓存命中率比之前还提高了20%。
有趣的是,如果只考虑缓存命中率,降低长时间游戏中的网络开销,可以考虑使用本地临时空间来进行缓存。依据微信官方的说明,本地临时文件只保证在小程序当前生命周期内有效,一旦小程序被关闭就可能被清理,即下次冷启动不保证可用。所以在长时间游戏过程中,可以自己设计一套映射办法,使用本地临时空间中的文件作为缓存文件读取,因为没有大小限制,可以极大提高缓存命中率。但是因为加载阶段下载公共图集等资源需要4-6s,项目更在乎第二次进入游戏的速度,所以我们没有做这方面的考虑。
关于性能优化我的一些思考
以上是基于H2项目优化时的一些经验,接下来这部分主要想分享一下我关于性能优化这方面的一些思考和感悟。作为一个零项目经验的人(因为头一年都在做SDK接入与开发,打包分发等移动应用相关的工作),从头到尾经历完整个项目的生命周期后,回过头来思考怎样才能做出一个性能表现不错的项目是一件很有意思的事情。
量化
如同市面上的CPU更新时都会和上一代进行算力对比一样,在我们对游戏进行性能优化的过程中,也一定要对前后的具体性能表现进行性能量化,差异对比。否则做了任何一个改动都只能从主观上去臆测,无法知道优化的有效性,也无法直观查看优化的结果。没有量化数据指导的优化工作以及迭代更新不但结果抽象,而且往往会陷入没有目标,没有反馈,优化效率低下,徒劳,甚至负优化的情形中去。
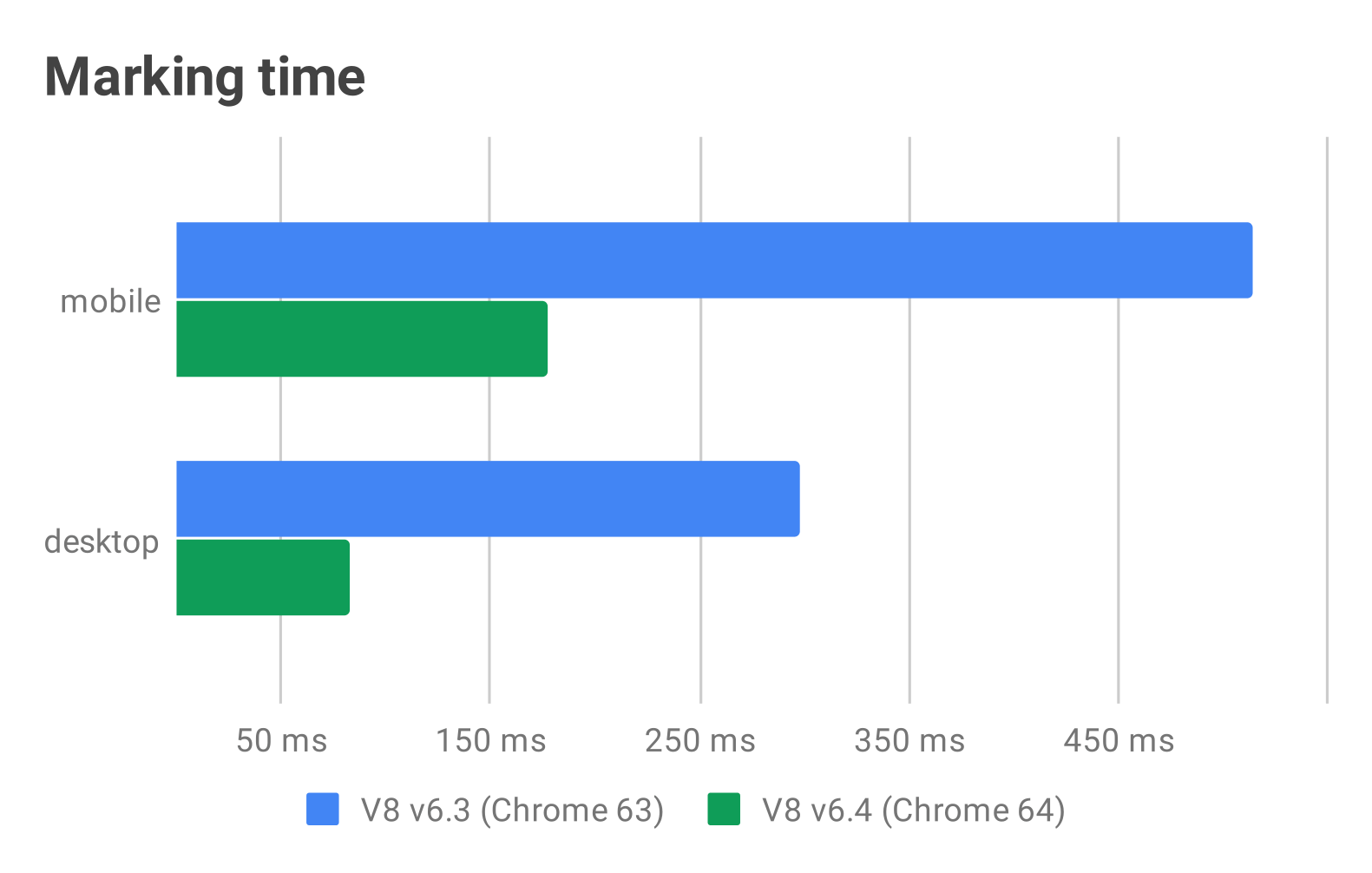
*如JavaScript V8引擎每次有新的技术迭代都会展示优化的结果*
性能优化离不开量化,而量化则离不开好的工具和模块设计。不过测量性能指标的工具有好有坏,最理想的往往是在设计功能模块时,就已经思考了如何量化这个模块的性能指标,并且随着模块的实现,相应的量化工具也写出来了。比如设计一个协议的收发模块,就要考虑如何方便量化协议的耗时。协议基类可以将收发协议拆分成若干个独立步骤,比如组装,发送,解析,执行,这样在后期量化性能指标的时候,便能非常方便的打点统计,数据清晰,哪里不符合标准也一目了然。在H2项目后期我排查场景、特效模块引起的内存泄漏时,颇有这种遗憾。当业务功能已经铺开或实现完全时,再重新设计模块和规则要求大家一起使用或遵守是不现实的。量化的工具不应该是单独于项目之外的东西,而是随着功能实现同时设计产出的东西。
那么具体怎么量化呢?这个取决于在做什么样的优化工作。和衡量算法一样,无非是时间和空间两个维度。
- 时间维度衡量:
- 各种模块执行耗时:如一帧Update中各模块的耗时,某个关键步骤或函数的执行时间,打开一个功能或页面需要的时间等。
- 一定时间内事件发生的次数:如同一个场景下一段时间内GC发生的次数,一段时间内某个函数循环的次数等。
- 空间维度衡量:
- 规模大小:如游戏使用的内存大小,显存大小,游戏内各种资源的大小,总包体大小等。
- 空间使用率:如内存中有大量相同的数据如纹理,mesh,动画,音频等,或者缓存了无效资源等。
量化结果需要前后对比才能凸显优化工作的价值,但是一定要注意控制条件变量。当掺杂多个变量时,性能优化前后的对比结果则毫无指导意义。
自动化监测
自动化是解放生产力的重要因素,而自动化监测性能数据则是在推进游戏开发进度的过程中预防性能表现失控的关键因素。没有自动化监测的工具,则意味着项目组需要投入人力,频繁检查性能表现,排查隐患。何况对人而言,在开发内容快速推进的时候,“排查”是一项费时费力,并且容易有遗漏的工作。在人力有限的情况下,这样做可能会导致开发进度被拖累。
在H2项目中,随着项目推进总共进行了2次相对集中的性能优化工作。从公司的视角而言,因为我们没有足够的人力持续性的监视着性能数据或者投入到性能优化的工作上去,所以每次只能集中一段时间投入2-3个人对项目的性能表现进行把控和优化。这非常可以理解,哪怕数百人的项目组也经常存在人力紧张的情况。但是问题是这些优化的时间节点往往是性能肉眼可见地出问题了(失控),项目要内测了,项目要上线了这些因素影响的。如果项目本身相对简单,或者初期就有了一定的开发规范,也没有大量的需求改动,那么游戏性能也不会有什么大问题。但是当项目复杂度提升到一定水平时,这样的工作安排往往捉襟见肘。而这就是自动化监测工具需要完成的工作:先于“人眼”报告出游戏的性能问题。
*市面上对产品进行性能、质量、兼容性测试的商业化测试软件PerfDog*
理想的情况下,从项目一开始便应该投入人力开发一些自动化工具监测性能表现。有别于市面上对完整游戏产品进行质量测试的商业测试软件如PerfDog UPR Airtest等等,这些工具理应随着功能模块的开发或规则的制定一起实现,关注一些具有项目个性化关键的性能指标,独立或嵌入模块之内。一般分以下两种形式:
- 独立于游戏外的静态检测工具,定期执行,扫描出不符合要求的性能相关问题,包括自动运行游戏的脚本。
- 嵌入游戏的动态监测工具,在以测试模式运行时发现问题会弹出警告,收集相关数据并上传到性能后台。
这些工具伴随着项目进度的推进,全程监测着性能数据是否符合要求。不必等到问题肉眼可见,一旦出现性能异常,项目组立刻就能响应派遣人力解决,并且制定出新的规范来指导后续的开发工作,避免同类型问题再次出现。显而易见,如果游戏开发到内测全程性能表现处于可控状态,那么最终游戏上线时性能表现也必然不会失控。
值得注意的是,这样的工具可能很容易实现,但是根据不同项目对不同性能数据设立不同的标准,则对游戏开发经验有很高的要求。即游戏性能与质量二者大多难以兼得,如何设置合理的性能预期也是十分重要的。
可视化
当你拥有一系列性能指标数据需要对比展示时,使用表格列出各项数据是最简单的,但是这样的形式往往不够直观。尤其是在数据项庞杂的时候,对比每一项数据显得尤其费力,没有重点,并且结论也不够显而易见。比如在寻找帧数剧烈变化的掉帧场景时,如果仅有包含近万条帧率数据的表格而没有折线图,那你很难找到帧率的抖动情况。并且,相比硬生生的丢出一堆数据而不做处理,绘制成可视化图表才是更具艺术、简洁、优雅的报告形式。在现代化工具的帮助下,这也不会耗费多少时间。一般情况下,对数据进行可视化也就这么几步:
- 通过性能测量工具收录数据
- 可能需要通过分析处理工具进行过滤和筛选,将值得关注的信息拣选出来
- 选择合适的图表形式绘制可视化报告
*基于JavaScript的开源可视化图表库ECharts示例*
图表形式的选择直接影响了报告的直观程度,最常见的帧率变化一般选择折线图,内存变化选择堆叠面积图(如Android Studio的Memory Profile),简单的耗时对比就用柱状图。
其他
设计封装
优秀的性能表现离不开优秀的设计和封装。一个模块最核心的部分封装好了,开发人员只需要往模块内部填充业务,哪怕代码水平参差不齐,写的再天马行空,项目也大概率不会出现严重的性能问题。举个例子,一个面板加载的资源和对象组件是否存在泄漏,这个就需要在设计UI模块之时加以考虑。例如我们可以在面板初始化时统一使用某个接口注册加载其依赖的资源和组件,面板销毁时同样由统一接口管理对应资源的清理。这样能有效避免组件或资源泄漏问题,并且即使出现个别代码加载未注册的资源时,也能及时发现并解决。
每个公司都有自己的代码标准或者开发规约,但是开发者执行的好与坏就是体现代码水平的差异了。好的设计与封装就如同硬性的规定,极大的提高了代码水平的下限。
重构
对模块的重构一定要时刻进行,尤其是在业务代码飞速增长的阶段。如同对待性能优化的态度不能是游戏做完再进行性能优化一样,对待重构的态度不可以是全部功能实现完再进行重构。比如在H2项目中,开发各个不同平台的同一功能时,都要判断平台类型,再去调用不同的实现。而在添加第二个各平台都需要的功能时,就要思考之前的设计是否合理,调用日志如何统一,如何兼容没有该功能的平台,考虑怎样设计能够方便之后的拓展和维护。根据经验,哪怕一个很小的模块,经过若干次代码的增长和不同人手的开发后,其结构或多或少的都会变得臃肿不堪,无法直视,大概率出现冗余,或者出现性能问题。严格来讲,Code Review与重构的时机,就应该像是内存分配器在每次分配内存前会检查是否要进行垃圾回收一样,添加代码前也要先整理一遍代码,思考是否合理,是否需要重构。
组内Code Review是一项很难在内部推广的事情,除了代码水平参差不齐的问题外,还有一些感性的因素形成阻碍,至少在公司尝试了两次推行组内Code Review失败后我是这么认为的。但是自己对自己写的代码进行Code Review,及时重构是非常有必要的。虽然在版本管理工具的帮助下,大家可以通过blame看到每行代码的作者,但是我认为每个程序员都应该出于本能的在自己写的代码片段“签名”,
Review&Refactoring是对自己工作的一种负责。
做的一些其他工作
除性能相关的优化工作外,作为引擎我还在H2项目中做了一些其他工作,这里简单列举一些:
- 基于Unity Editor拓展开发2D场景编辑器
- 开发Laya IDE拓展(VSCode插件)给美术使用
- 开发了三端(浏览器包括Native WebView,iOS,Android)的本地日志记录与上报模块
- 三端的视频播放功能组件
- 三端的闪屏实现
- 资源更新版本管理机制的研究与资源缓存nginx的配置
- JavaScript报错堆栈收集与解析服务
- 三端的基础模块如获取设备信息,内存信息,权限申请的开发
- 优化Laya的gulp编译流程,增量编译
- 解决了微信小游戏上线的各种问题包括分包、WSS、闪屏、视频播放等
- 修复了Laya引擎底层的若干漏洞
- 开发与接入微信/QQ小游戏客户端聚合js SDK
- 实现2D的实时阴影
- 安卓WebView端接入X5内核
最后
分享了这么多,那么如果给一个既定的项目给我,我该如何下手去优化呢?或者说,关于性能优化,有没有一些普适性的思路和常见的解决办法呢?这部分就留到下一篇文章去讨论了。


